机器之心报道
编辑:Panda、蛋酱
人类有两只眼睛来估计视觉环境的深度信息,但机器人和VR头社等设备却往往没有这样的「配置」,往往只能靠单个摄像头或单张图像来估计深度。这个任务也被称为单目深度估计(MDE)。
近日,一种可有效利用大规模无标注图像的新MDE模型DepthAnything凭借强大的性能在社交网络上引起了广泛讨论,试用者无不称奇。
甚至有试用者发现它还能正确处理埃舍尔()那充满错觉的绘画艺术(启发了《纪念碑谷》等游戏和艺术):

从水上到水下,丝滑切换:

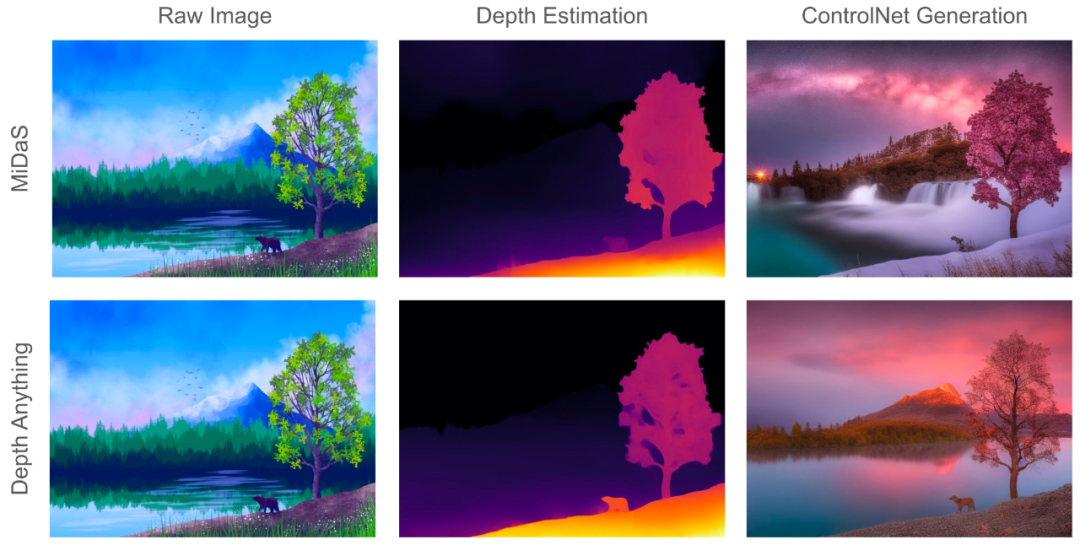

理论上说,基础模型可用于解决单目深度估计(MDE)问题,即基于单张图像估计深度信息。这类技术在机器人、自动驾驶、虚拟现实等领域都有广阔的应用前景。但由于难以构建带有数千万深度标签的数据集,这一问题还少有研究者探索。
此前的MiDaS算得上是这个方向上的一项开创性研究,其基于一个混合标注的数据集训练了一个MDE模型。尽管MiDaS展现出了一定程度的零样本能力,但受限于其数据覆盖范围,其在某些场景中的表现非常差。
来自香港大学、TikTok等机构的研究者提出的DepthAnything,则是一个更为实用的解决方案。
论文标题:DepthAnythingUnleashingthePowerofLarge-ScaleUnlabeledData
论文地址:
项目主页:
演示地址:
该研究的目标是构建一种能在任何情况下处理任何图像的简单却又强大的基础模型。为了做到这一点,该团队采用了一种方法扩大数据集的规模:设计了一种数据引擎来收集和自动标注大规模无标注数据(约6200万)。这能显著扩大数据覆盖范围,并由此可以降低泛化错误。
为了保证数据扩展的质量,研究者探索了两种简单却有效的策略。
第一,利用数据增强工具创建一个难度更高的优化目标。这会迫使模型主动寻找额外的视觉知识并获取鲁棒的表征。
第二,开发一种辅助监督机制,可强制模型从预训练编码器继承丰富的语义先验知识。
团队使用6个公共数据集和随机拍摄的照片评估了新方法的零样本能力,其泛化能力非常出色。更进一步,使用来自NYUv2和KITTI的度量深度信息对模型进行微调后,新模型获得了新的SOTA结果。
这篇论文的主要贡献包括:
强调了大规模、低成本和多样化无标注图像的数据扩展对MDE的价值。
指出了在联合训练大规模有标注和无标注图像方面的一个重要实践方法:不是直接学习原始无标注图像,而是为模型提供更困难的优化目标,让其学会使用额外的知识。
提出从预训练编码器继承丰富的语义先验,从而实现更好的场景理解,而不是使用辅助性语义分割任务。
新模型的零样本能力超过MiDaS-BEiT_L-512。不仅如此,使用度量深度进行微调后,新模型的表现更是显著超过ZoeDepth。
DepthAnything
TikTok的这项研究使用了有标注和无标注图像来实现更好的单目深度估计(MDE)。用数学形式表示,可以将有标注和无标注集分别表示成:
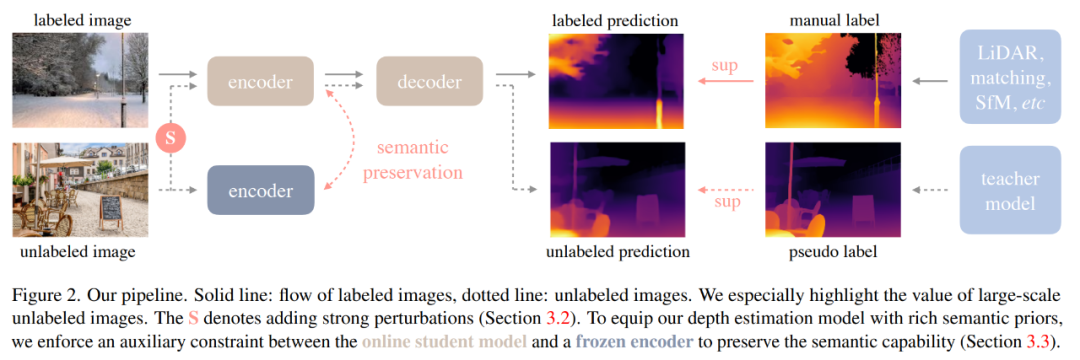
这里的目标是根据D^l学习得到一个教师模型T。然后,使用T给D^u分配伪深度标签。最后,使用有标注集和伪标注集的组合数据集训练一个学生模型S。图2是一个简单图示。
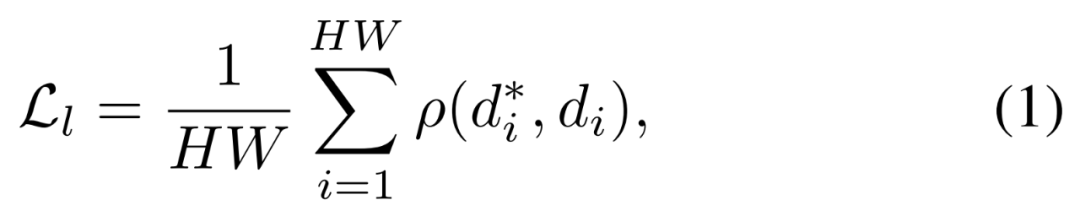
学习有标注图像
这个过程与MiDaS的训练过程类似。具体来说,深度值首先会通过d=1/t被转换到视差空间(disparityspace)中,然后再把每张深度映射图归一化到0~1范围内。为了实现多数据集联合训练,该团队采用了仿射不变损失。
这样一来就可以忽略每个样本的未知尺度和偏移。
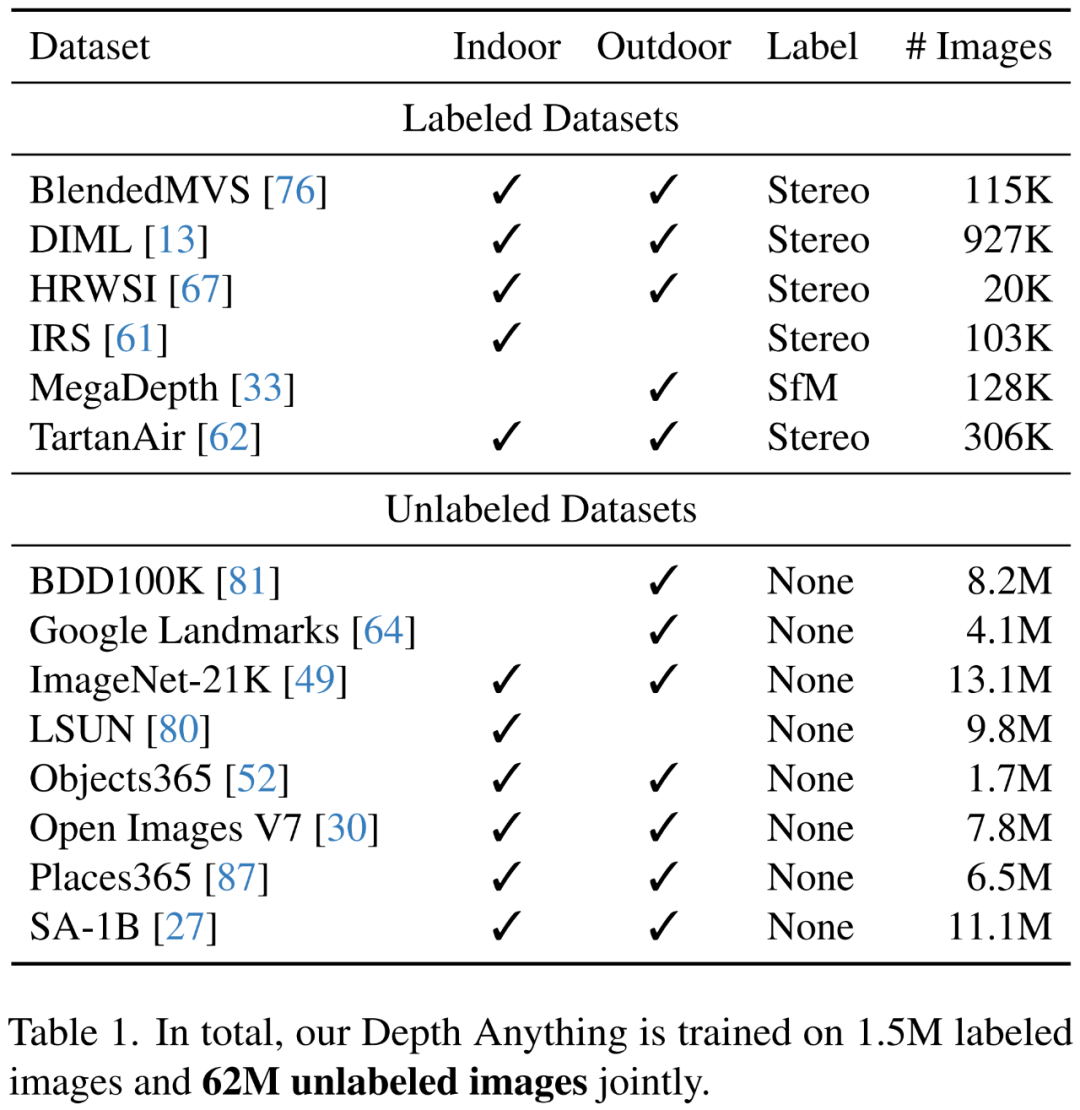
为了得到稳健的单目深度估计模型,他们从6个公共数据集收集了150万张有标注图像。表1列出了这些数据集的详情。
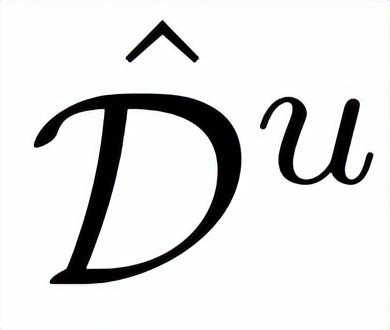
不仅如此,为了增强从这些有标注图像学习到的教师模型T,他们还采用了DINOv2预训练权重对编码器进行初始化。在实践操作中,该团队的做法是使用一个经过预训练的语义分割模型来检测天空区域并将其视差值设置为0(即最远)。
解放无标注图像的力量
这正是这项研究的主要目标。至于无标注图像源,该团队选择了8个大规模公共数据集,保证了多样性。这些数据集总共包含6200多万张图像。详情见表1下半部分。
技术上讲,给定之前获得的MDE教师模型T,可在无标注集D^u上得到预测结果,从而得到一个伪标注集:
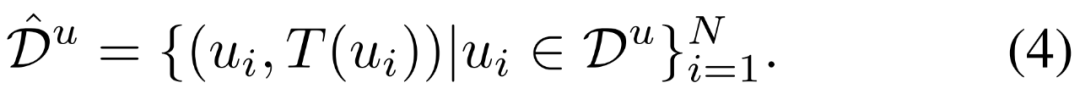

该团队引入了两种形式的扰动:一种是强颜色扭变,包括颜色抖动和高斯模糊;另一种是强空间扭曲,也就是CutMix。
尽管方法很简单,但这两种修改方法可让大规模无标注图像显著提升使用有标注图像训练的基准模型。
至于CutMix,它最早是为图像分类提出的技术,目前还很少用于单目深度估计。该团队的做法是先在空间上插值一对随机的无标注图像u_a和u_b:
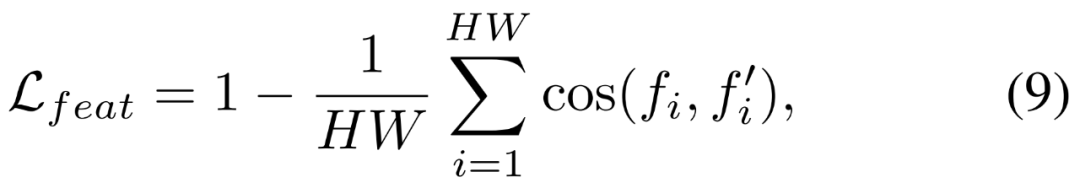
在处理无标注图像时,该团队设定使用CutMix的概率为50%。输入给CutMix的无标注图像已经在颜色上经历过强扭变,但给教师模型T进行伪标注的无标注图像却是干净的,没有任何扭变。
语义辅助型感知
这项研究首次尝试了组合使用RAM+GroundingDINO+HQ-SAM来为无标注图像分配语义分割标签。经过后处理之后,这得到了一个包含4000个类别的类别空间。
在联合训练阶段,该模型的任务使用一个共享的编码器和两个单独的解码器得到深度预测结果和分割预测结果。不幸的是,一番试错之后,该团队没能提升原始MDE模型的性能。
因此,他们的目标就变成了训练更多能提供信息的语义信号,以作为辅助监督信号助力深度估计任务。
该团队表示:「DINOv2模型在语义相关任务的强大表现让我们大受震撼。」
因此,他们提出通过一个辅助特征对齐损失将其强大的语义能力迁移到新的深度模型。其特征空间是高维且连续的,因此包含的语义信息比离散掩码更丰富。该特征对齐损失的数学形式为:
实验及结果
研究者使用了DINOv2编码器进行特征提取。所有标注的数据集都简单地合并在一起,无需重新采样。无标注的图像由使用ViT-L编码器的最佳教师模型标注,每批标注和无标注图像的比例设定为1:2。
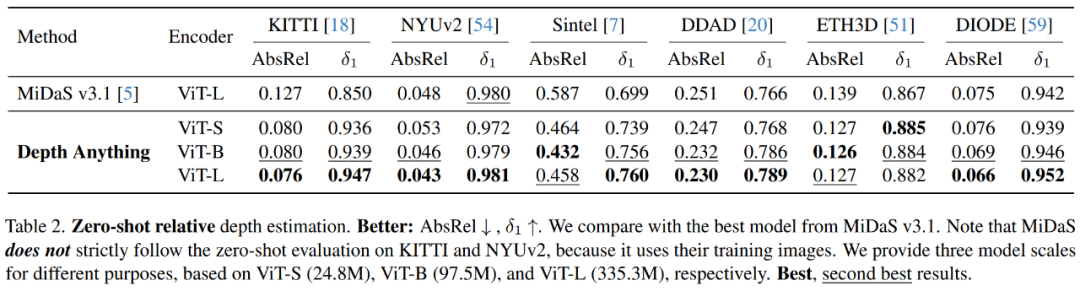
零样本相对深度估计
研究者在六个具有代表性的不可见数据集KITTI、NYUv2、Sintel、DDAD、ETH3D和DIODE上全面验证了DepthAnything模型的零样本深度估计能力,并将其与最新中的最佳DPT-BEiT_L-512模型进行了比较,后者使用的标注图像比前者多。
如表2所示,在均使用ViT-L编码器的前提下,在广泛的场景中,DepthAnything在AbsRel和δ_1度量上都大大超过了MiDaS的最强模型。
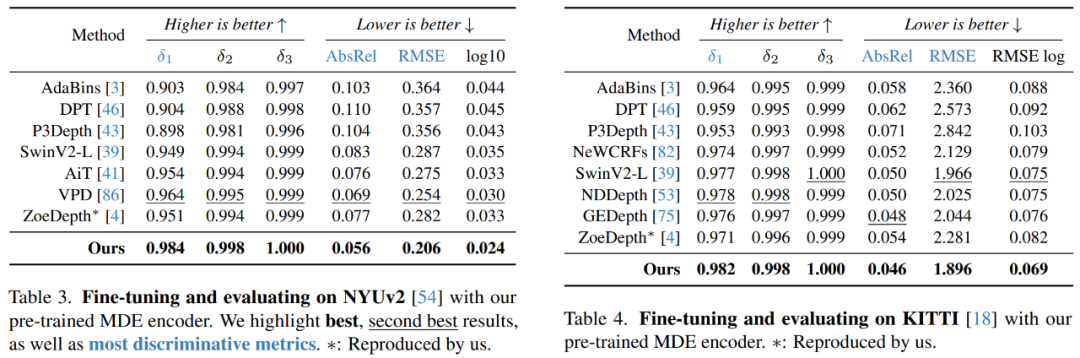
面向度量深度估计的微调
研究者进一步研究了DepthAnything模型,将其作为下游度量深度估计的一种有潜力的权重初始化方法。
两种有代表性的情况如下:
1)域内度量深度估计,即在同一域内对模型进行训练和评估。如NYUv2表3所示,DepthAnything模型明显优于之前的最佳方法VPD,δ_1(↑)从0.964→0.984,AbsRel(↓)从0.069提高到0.056。表4中的KITTI数据集也有类似的改进。

2)零样本度量深度估计,即模型在一个域(如NYUv2)上进行训练,但在不同域(如SUNRGB-D)上进行评估。如表5所示,在大量未见过的室内和室外场景数据集中,DepthAnything比基于MiDaS的原始ZoeDepth得出了更好的度量深度估计模型。
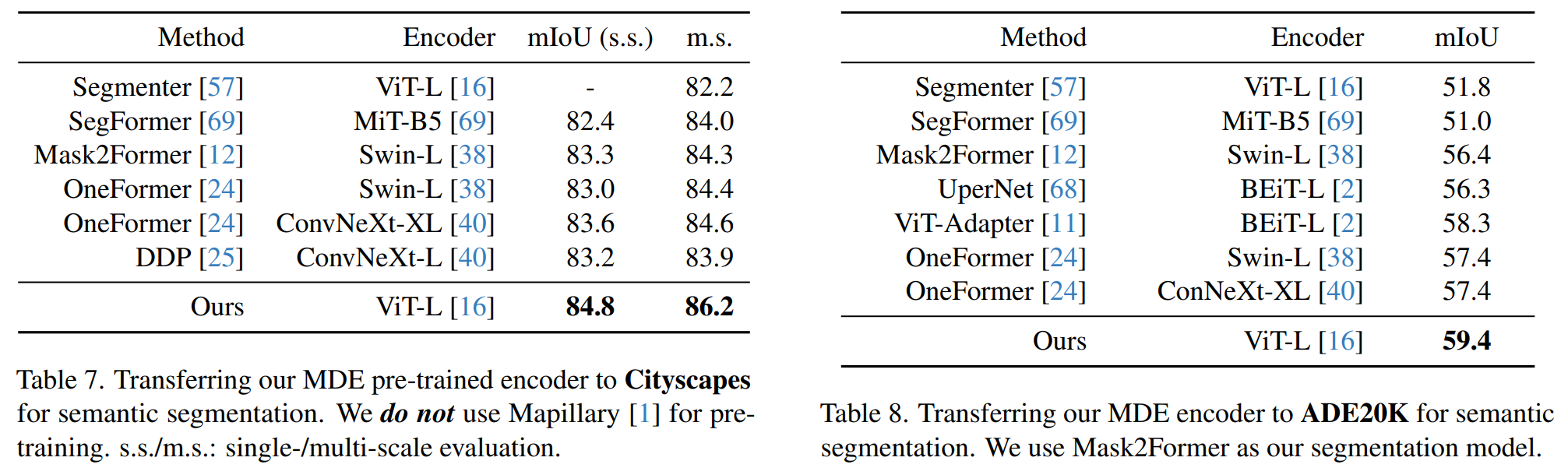
面向语义分割进行微调
在本文方法中,研究者设计了MDE模型,通过简单的特征对齐约束,从预训练编码器中继承丰富的语义先验。随后,研究者检验了MDE编码器的语义能力。
如Cityscapes数据集的表7所示,研究者从大规模MDE训练中获得的编码器(86.2mIoU)优于从大规模ImageNet-21K预训练中获得的现有编码器,例如Swin-L(84.3)和ConvNeXt-XL(84.6)。表8中的ADE20K数据集也有类似的观察结果。
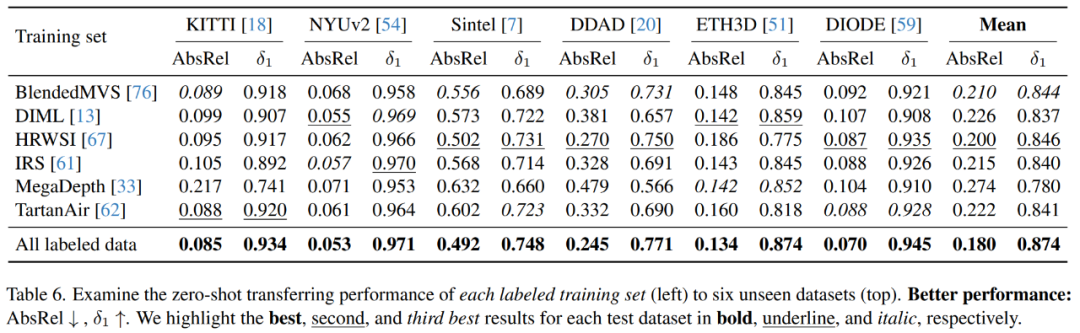
消融实验
在消融实验中,研究者使用了ViT-L编码器。表6展示了每个训练集的零样本迁移性能。
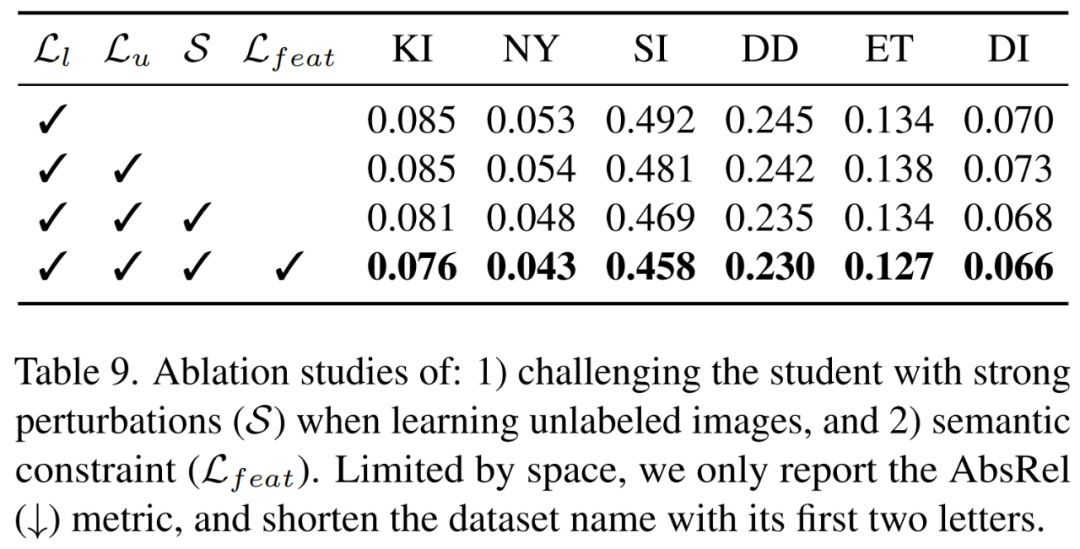
如表9所示,简单地添加带有伪标签的无标注图像不一定为模型带来增益,大规模的无标注图像能够显著增强模型的泛化能力。
另外,附一则研究团队的招聘信息:
联系方式:bingyikang@
视觉和多模态大模型方向
实习生和全职都有招聘!
Base地点:北京,新加坡,SanJose
对于优秀的实习生,可以提供远程实习机会!
联系方式:bingyikang@














